Since Isaac Asimov formulated them some 80 years ago, his Three Laws of Robotics have been the subject of much discussion, debate, imitation, extension and satire. Asimov himself added a "zeroth law", and organizations such as the Engineering and Physical Sciences Research Council (EPSRC) and the Arts and Humanities Research Council (AHRC) in the U.K. have formulated their own laws, or “Principles of Robotics”. Published in 2011, and clearly influenced by a new awareness of the power that artificial intelligence (AI) and data mining combined with psychology can wield over humans, these principles include statements such as “It should always be possible to tell a robot from a human”. Asimov fans will remember the importance of psychologists in his Foundation series.
Despite the great strides we have made in robotics and autonomous systems in recent decades, we are as yet nowhere near building robots with the agency implied by Asimov’s Laws. Robots don’t have the capacity to make moral decisions. However, we who design and build robots do have this capacity, and thus we have the responsibility of ensuring that the robots we build don’t unwittingly become agents of injury or destruction. If we include the Zeroth Law, we can paraphrase Asimov’s laws as follows: Laws 0 and 1: Do no harm; Laws 2 and 3: Do as instructed unless the instructions contravene Laws 0 or 1.
For us as designers and builders of robots, this means that our creations must run as intended, so that they don’t inadvertently cause harm. In other words, our robots must not only perform the tasks for which they have been designed, but they must also be functionally safe.
Functional Safety
Functional safety is the capacity of a safety-related system to function as it is expected to function. It is the continuous operation of a safety-related system performing its primary tasks while ensuring that persons, property and the environment are free from unacceptable risk or harm.
No System is Error-Free
It is possible to design a software system that is completely free of errors. Unfortunately, such software would most probably need to be so simple that it could do nothing useful that couldn’t be done by today’s hardware. Thus, when we design and build a functionally safe software system, we must assume that it is functional (it does something useful) and it is not free of errors, which create faults that can, ultimately, cause failures.
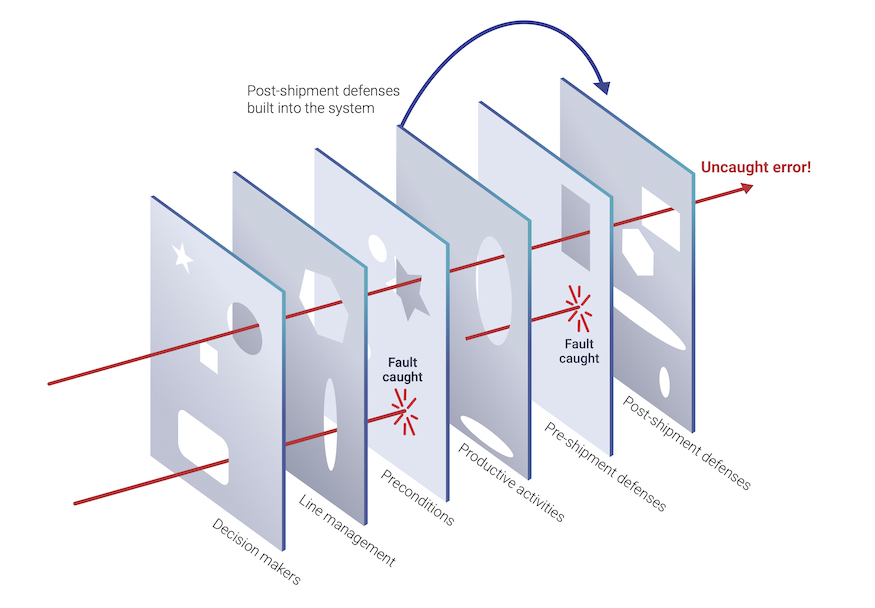
The diagram below, adapted from James Reason’s 1990 Human Error, illustrates how an error can become a failure. Notice that no defence is absolute; there will always be uncaught errors. This point is particularly relevant to software. There will always be Heisenbugs—elusive, irreproducible bugs, so the software must be designed to behave in an orderly manner should an uncaught error cause a failure. It must move to a pre-defined Design Safe State; for example, a robot about to go rogue must shut down before it does so.
Figure 1. An error becomes a failure (adapted from James Reason).
A New Context Means a New System
It is significant that agencies such as the U.S. Food and Drug Administration (FDA) evaluate devices rather than their discrete parts. The wisdom of this practice is easily grasped from an example, not from medicine, but from rocketry: the Ariane 5.
Thirty-seven seconds after it was launched on June 4th, 1996, the European Space Agency’s (ESA) new Ariane 5 rocket rained back to earth in pieces. This failure was caused by what became one of the best-known instances of software that had been exhaustively tested and even field proven—more accurately, sky-proven—ceasing to function correctly even though it had not been changed. What had changed was the context in which the software ran.
The acceleration of the Ariane 5 was greater than that of its predecessor, the Ariane 4, for which the Ariane 5’s Inertial Reference System (Système de Référence Inertiel—or SRI) had originally been designed and tested. Though the SRI itself had not changed, in its new context—the more powerful Ariane 5—the software was unable to function as required.
The lesson we can draw from this twofold. First, any change in a functionally-safe system or its context may be significant and potentially dangerous. Second, designing a functionally-safe system with pre-certified components, such as the QNX® OS for Safety and the QNX® Hypervisor for Safety, is an excellent strategy that can speed product delivery and certification, but this approach is in itself insufficient: we must demonstrate functional safety in every context in which the system will be used.
For example, if we build a control system for a robot that will operate in the deep ocean then implement it for use in outer space, we must ensure that the system will function as required in its new environment. We must be sure, for instance, that the system will not fail due to greater neutron flux outside the Earth’s atmosphere.
Limiting Scope
One of our first tasks when designing a safety-critical system is to define the system and its limits. That is, we must clearly define the components that are safety-critical, and establish a clear demarcation between them and components that are not safety-critical. This definition and demarcation serves a double purpose.
First, it allows us to focus our efforts on proving the functional safety of the relevant components rather than of the entire system. For example, in a software system running a medical ventilator, the software managing air pressure, the gas mix and the sensors feeding information back to these systems are safety-critical, while software uploading data to the patient’s medical records may not be. It makes no sense, then, to spend time and effort ensuring that the data upload software is other than reasonably reliable.
Second, a clear demarcation between safety-critical and non-safety components helps us ensure that the safety-critical software is isolated from the non-safety software, and is free from interference, either inadvertent or malicious. In a system built with a QNX microkernel the architecture itself provides the basis for such a separation: device drivers are outside the kernel space, for example, so a driver failure won’t bring down the system. Going a step further, a hypervisor can provide containment and isolation for entire systems.
Note that the definition of safety-critical components should include a temporal demarcation. If a safety-critical system must run for, say, 24 months without rejuvenation (e.g., a cold restart), then we must demonstrate that it can do so. However, if the system needs to run only for six hours, then proving that it can run without failure for longer is wasted effort. For example, if a system is to be used in an aircraft there is no value in proving it for use beyond the range of the aircraft, plus safety buffer. In fact, changes to extend the life of the system might even introduce errors. If the system is ported to a new aircraft, though, everything changes (see “A New Context Means a New System” above).
Testing
The complexity of today’s software systems means that we can no longer assume that a system is deterministic. On the contrary, we must assume that we will never know every state and state transition in the system and that, therefore, we will never test them all. In fact, The Engineering Safety Management Yellow Book 3, Application Note 2: Software and EN 50128, published by Railway Safety on behalf of the UK railway industry almost two decades ago even states that “if a device has few enough internal stored states that it is practical to cover them all in testing, it may be better to regard it as hardware.”[1]
This fact doesn’t mean that we shouldn’t test our software. What is does mean is that to ensure the functional safety of our systems, in addition to testing we must employ other methods such as formal design and proven-in-use analysis. At BlackBerry® QNX®, for instance, we are using Ada for some critical projects because it supports design by contract and proving, which can reveal bugs at compile time.
A Note About Security
Entering the third decade of the 21st century it is a truism that no robot is an island. Discrete and unconnected systems are of the last century. The advantages of connectivity are such that few software systems can do without it: a medical ventilator uploads patient data; a drone shares location information with other drones; a forklift checks incoming inventory with the delivery truck.
Connectivity means vulnerability, however. Thus, when we design our functionally-safe systems, we must ensure that their integrity can’t be compromised by malicious actors. We must ensure that they are secure. How, precisely, we can do this requires a comprehensive security strategy involving everything from security protocols to the OS architecture—a microkernel architecture offers a reduced attack surface, for instance. We’ll be writing about security in a future post, so please check back with us soon.
The Future
We’re still a very long way off from a world where robots have moral agency. But as we build more sophisticated systems, the complexities of our task to meet our moral responsibilities increases. Building on a trusted foundation doesn’t absolve us of responsibility, but it can lighten the practical burden of demonstrating—to ourselves first of all—that we have done everything to ensure that our robots will obey Asimov’s Laws.
If you need to know about these topics as they apply to BlackBerry QNX products or services, please contact us, or stay tuned for future blog posts here.
[1] Application Note 2: Software and EN 50128. London: Railway Safety, 2003. p. 3.